

© 2018 IPE
© 2018 IPE

IPE travaille depuis plus maintenant un an au développement d’un modèle pleinement opérationnel dans OASIS LMF. Le modèle que nous avons conçu concerne les risques liés à la grêle en France, et nous sommes déjà en train de l'étendre à l'Europe.
La publication suivante vise à couvrir les aspects techniques liés à la mise en œuvre d'un modèle dans le cadre d'OASIS LMF.

Un modèle CAT est généralement résumé en utilisant 4 blocs principaux :
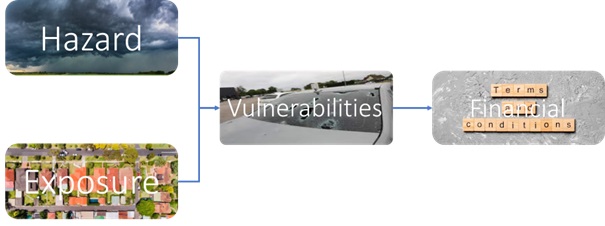
La raison pour laquelle nous avons choisi OASIS LMF est qu'ils normalisent/mettent en œuvre les modules suivants :
L'exposition est normalisée selon l'OED (Données d'exposition ouvertes). Par conséquent, les spécifications des données d'entrée sont prédéfinies avec leurs avantages et inconvénients, mais elles ne sont pas spécifiques au modèle, du moins. Bien que les formats d'exposition AIR et RMS ne soient pas faciles, ils peuvent être traduits directement en OED.
Le module financier est précodé, de sorte que l'ensemble du module n'a pas besoin d'être recodé et optimisé.
Les blocs Aléa et les vulnérabilité sont des formats prédéfinis, mais en personnalisant, ils permettent quelques ajustements si vous personnalisez l'analyse préalable et le script de clé de serveur.
Ainsi, développer un modèle dans le cadre d'OASIS LMF vous permet de "vous concentrer" sur les modules principaux d'un modèle CAT, à savoir les dangers et les vulnérabilités.
La structure principale d'un modèle CAT dans OASIS LMF est la suivante :
Les blocs sont synthétisés comme suit :
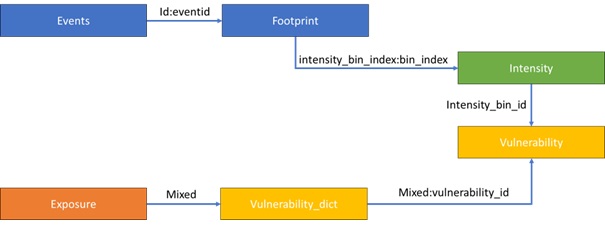
Facile à dire ! Mais plongeons plus en détail dans l’implémentation !
Comme tout autre modèle CAT, l'exposition est correctement qualifiée en termes de géocodage, ce qui signifie que tout type de localisation est acceptable, qu'il s'agisse de lat/lon, de code postal, de niveaux administratifs ou de niveau de pays.

L'Empreinte que vous avez est fondamentalement conçue à un ou plusieurs niveaux, mais pas à tous... C'est à ce moment-là que le niveau de géocodage intervient, car les portefeuilles viennent avec des résolutions mixtes et vous devez les prendre en charge. OASIS n'intègre aucun système de géocodage, vous devez donc tout encoder.
Notre modèle a été encodé au niveau le plus granulaire, c'est-à-dire les lat/lon et les zones raffinées appelées codes INSEE, mais les expositions au niveau de la ville ou des niveaux administratifs (région, département, canton, commune pour la France) ne pouvaient pas correspondre à la résolution de notre modèle.
Nous avons donc intégré des processus d'agrégation du danger par commune, ville, département et région, ce qui nécessitait des hypothèses basées sur des informations externes telles que la surface, la densité de population, le nombre de maisons. Les résultats n'étaient évidemment pas acceptables car les expositions agrégées n'étaient pas décomposées par OASIS comme ils le pensaient. En fin de compte, les expositions agrégées étaient toutes corrélées, ce qui entraînait des pertes plus faibles en périodes de retour faibles et des résultats plus élevés en périodes de retour élevées. Le processus d'agrégation ne fonctionnait que pour un risque unique détaillé.
Nous avons donc dû mettre en œuvre un script d'analyse préalable considérable qui est exécuté avant l'exécution du modèle pour décomposer l'exposition agrégée. Ce n'était clairement pas une tâche facile, car chaque exposition codée au niveau d'une région du pays devait être décomposée en localisation probabiliste de la région, puis du département, puis du canton, puis de la ville, puis du code commune, pour gérer tout type de codage.
Purement technique, pourrait-on dire, simplement un problème de mappage en utilisant des hypothèses pour décomposer l'exposition... Il suffit d'inclure l'exponentielle de décomposition où une localisation au niveau du pays serait décomposée en 36 000 emplacements probables. Des données d'exposition mal codées conduisent à des milliards d'emplacements probables et OASIS ne s'exécutait pas jusqu'au bout, faute de mémoire.
Pour le régler, nous avons dû utiliser des serveurs puissants pour exécuter chaque exposition agrégée pour chaque niveau donné jusqu'au niveau détaillé, et exécuter une optimisation pour choisir les meilleurs emplacements limités à 100 avec au moins une sous-région représentée pour minimiser au mieux l'erreur de sortie. Ce problème de géorésolution et d'optimisation nous a pris près de 3 mois pour trouver une solution et la mettre en œuvre.
La vulnérabilité est assez simple : pour une exposition et une classe d'intensité, vous avez une distribution des pertes totales. Mais attendez, un appartement résidentiel n'a pas la même vulnérabilité qu'une maison résidentielle. D'accord, il existe essentiellement 195 codes OED d'occupation, donc autant de courbes de vulnérabilité.
Attendez, une maison résidentielle avec une couverture de toit en chaume, en argile, en zinc, en feutre, en bois, en aluminium ne réagit pas de la même manière. Il y a 28 types de couverture de toit différents, soit 195 * 28 = 5420 courbes de vulnérabilité différentes.
Ajoutons le type de construction, ce qui donne 195 * 28 * 210 = 1 146 600 courbes de vulnérabilité.
Dans notre modèle, nous avons dû introduire des spécificités géographiques, ce qui a fait exploser le nombre de courbes de vulnérabilité à des centaines de millions de courbes. Pour résoudre ce problème, nous avons dû simplifier considérablement le problème et contourner le processus OASIS LMF à tous les niveaux :
Mappage de toutes les occupations à leurs occupations générales (RÉSIDENTIEL, AGRICULTURE, INDUSTRIEL, COMMERCIAL).
Remplacement des occupations spécifiques qui ont leurs propres courbes de vulnérabilité.
Remplacement des vulnérabilités qui sont conçues en fonction de la construction plutôt que de l'occupation (principalement pour les types de construction en mer et les types de construction automobile qui n'ont pas d'occupation spécifique).
Remplacement des courbes de vulnérabilité qui sont une combinaison de la classe de construction * classe d'occupation.
Remplacement des courbes de vulnérabilité qui ont des modificateurs secondaires, principalement la couverture de toit dans notre cas.
Remplacement des courbes de vulnérabilité avec une localisation définie pour un ensemble d'occupations génériques.
Nous avons ainsi considérablement réduit le nombre de courbes de vulnérabilité à quelques centaines.
La principale difficulté à laquelle nous sommes confrontés maintenant est l'adaptation réelle aux récoltes qui diffère considérablement de l'immobilier, car dans l'immobilier, la valeur assurée est supposée stable sur une année, tandis que dans les récoltes, la perte dépend fortement du temps. En ce qui concerne les cultures d'hiver, une grêle en juin sera très dévastatrice, tandis qu'une grêle en août n'aura aucun effet sur elles (les récoltes étant terminées), mais elle détruirait les cultures de printemps...
La vulnérabilité devient un problème dépendant du temps. N'ayant pas résolu tout cela, notre prototype consistait à dupliquer chaque exposition 12 fois avec une attribution mensuelle, à créer une courbe de vulnérabilité mensuelle basée sur le type de culture et à attribuer et post-traiter les résultats détaillés pour sélectionner la perte du mois donné en utilisant la présélection d'occurrence pour tout avoir.
La solution n'est pas du tout idéale car elle multiplie par 12 le nombre d'expositions à traiter et à exécuter, en plus de devoir exécuter un post-traitement pour sélectionner la perte adéquate en fonction du mois d'occurrence. Cela parce qu'OASIS permet une mise en correspondance avec les courbes de vulnérabilité pour une exposition, mais pas pour une exposition croisée ou une dépendance temporelle.
La demande de surplus est essentiellement une inflation pour les événements majeurs... Après un événement majeur, il y a une pénurie de matériaux de construction, par exemple les tempêtes de grêle entraînent une pénurie de tuiles. Le prix des tuiles s'enflamme bien au-delà de la normale en raison de la pénurie sur le marché. L'impact n'est pas linéaire, car il y a des points d'inflexion avec des effets binaires. Cela ne peut pas être intégré dans les modèles OASIS. Pour ce faire, nous avons également dû post-traiter les pertes. Mais étant donné la charge élevée des portefeuilles, nous ne pouvions pas suivre chaque perte avec une répartition par occupation, nous avons donc dû simplifier le vecteur en utilisant des seuils de périodes de retour pour appliquer des facteurs de charge. La modélisation n'étant pas idéale, nous ne l'avons pas encore mise en production.
Actuellement, OASIS s'exécute soit sur un serveur, soit sur une image Docker. Le traitement est multiprocesseur et nous avons eu des allers-retours avec OASIS pour améliorer certains blocs de calcul. Il y a encore un point où vous ne pourrez pas exécuter de grands portefeuilles en fonction de votre configuration, car OASIS est un script python et charge à la fois le account et le location de l'OED. Si votre serveur ne peut pas tout charger, vous vous retrouvez avec un plantage et OASIS ne peut pas les découper en morceaux. Actuellement, nous exécutons une session de 32 Go avec 8 processeurs, nous avons identifié le point de rupture à une taille de fichier de location de 8 Go. Au-dessus, OASIS se bloquera car il ne pourra pas charger l'exposition.
Afin d'augmenter cette limite d'OASIS, nous avons conçu un script en R (qui consomme moins de mémoire que Python) pour charger les fichiers account et location. Nous divisons ensuite les account et locations en sous-OED, exécutons OASIS en séquence et réagrégeons les résultats pour recomposer les courbes d'événements extrêmes.
Le découpage n'est pas idéal car nous n'avons que la moyenne des événements et pas les pertes échantillonnées des événements, et cela prend beaucoup de temps pour exécuter une séquence de découpage et un post-traitement, mais cela permet au moins de gérer certains grands portefeuilles. Nous ne pouvons pas traiter de grands portefeuilles à ce stade.
Nous pensons toujours qu'OASIS a été la bonne solution, même s'il manque quelques éléments. Nous espérons qu'OASIS améliorera dans un futur proche les points suivants :
Le développement d'un modèle a été tout un parcours, cela nous a pris plus d'un an, environ 6 mois pour développer le modèle lui-même et 6 mois pour l'implémenter dans OASIS LMF. À l'avenir, l'implémentation d'OASIS LMF sera plus simple en connaissant les limites et la manière de les gérer.
Pour résumer, le développement et la mise en œuvre ont été un parcours très difficile, bien au-delà de ce que nous avions initialement anticipé, et parfois je doute vraiment que nous puissions y arriver. C'est là qu'OASIS LMF nous a apporté une aide précieuse et un soutien pour réussir.
Je tiens à remercier tout particulièrement :
Johanna Carter pour toute l'aide sur la spécification de l'OED.
Ben Hayes pour tout le soutien et la coordination.
Stephane Struzik pour tout le soutien technique, le débogage et l'optimisation qu'il a été en mesure de fournir rapidement.
Matt Donavan pour son engagement.
Dickie Whitaker pour tout ce qu'il a fait, son sens de l'humour et son soutien pour faire avancer les choses.
Nous continuons à améliorer notre modèle en l’étendant à l’Europe, et nous essaierons également d’organiser un événement OASIS l'année prochaine à Paris, STAY TUNE !
Si vous êtes intéressé ou avez des questions sur la mise en œuvre, n'hésitez pas à me demander, je suis là pour aider.